NyayaAnumana & INLegalLlama: The Largest Indian Legal Judgment Prediction Dataset and Specialized Language Model for Enhanced Decision Analysis
Building a Diverse Legal Dataset
To address the scarcity of large-scale, diverse legal datasets in India, a comprehensive resource named NyayaAnumana has been developed. It includes over 702,000 preprocessed case documents sourced from Supreme Court, High Courts, District Courts, Tribunal Courts, and daily orders. This wide coverage ensures representation across judicial levels, case types, and legal complexities. NyayaAnumana stands out as the most extensive and diverse dataset for Indian legal judgment prediction, offering a solid foundation for building robust and realistic AI models tailored to the nation's legal landscape.
INLegalLlama Model Explanation and Interface Overview
Developing a Specialized Legal Language Model
To harness the potential of the NyayaAnumana dataset, a domain-specific generative language model named INLegalLLaMA was introduced. Based on the LLaMA architecture, this model undergoes a two-step training process: continued pretraining on Indian legal texts to embed deep domain knowledge, followed by supervised fine-tuning on judgment prediction tasks. INLegalLLaMA is designed to understand the semantic and structural intricacies of Indian judicial language, allowing it to generate legally coherent predictions and explanations, which are vital in high-stakes applications like legal decision support systems.
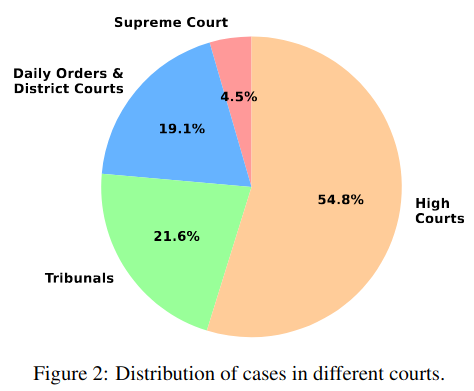
Distribution of source of cases in NyayaAnumana dataset.
Methodology for Judgment Prediction and Explanation
The study employs a dual-task framework for legal judgment prediction and explanation. For prediction, transformer-based models like InLegalBERT and LLMs perform binary/ternary classification by splitting lengthy legal documents into 512-token chunks with overlapping windows, addressing context limitations. The explanation component leverages INLegalLlama to generate human-readable justifications, evaluated using lexical metrics (ROUGE, BLEU), semantic similarity (BERTScore), and expert reviews. Expert evaluations rated the model’s explanations 3.54/5 on a Likert scale, showcasing near-expert alignment in rationale clarity.
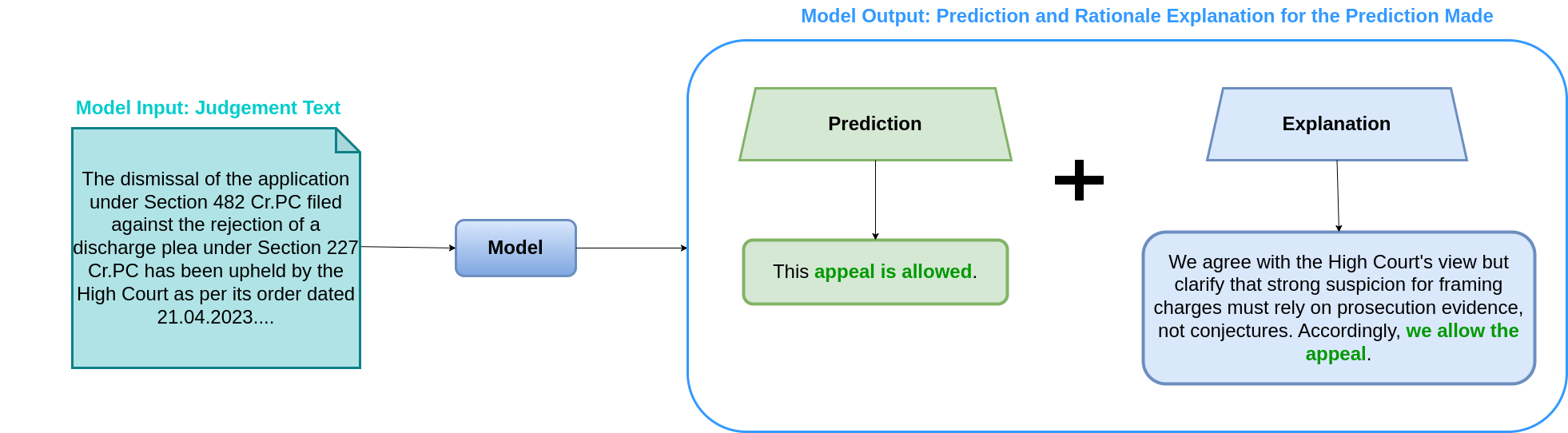
Model diagram for judgement prediction.
Key Findings and Model Performance
Key findings reveal 10–15% accuracy gains for models trained on NyayaAnumana compared to ILDC-trained counterparts, underscoring the dataset’s superior quality. INLegalLlama achieved 76.05% accuracy in explanation tasks, outperforming LLaMa-2 (57.26%) and GPT-3.5, with tests confirming its generalization to future cases. Incorporating diverse court hierarchies (e.g., High Courts) enhanced model robustness, while temporal validation ensured reliable performance on unseen data from 2020–2024.
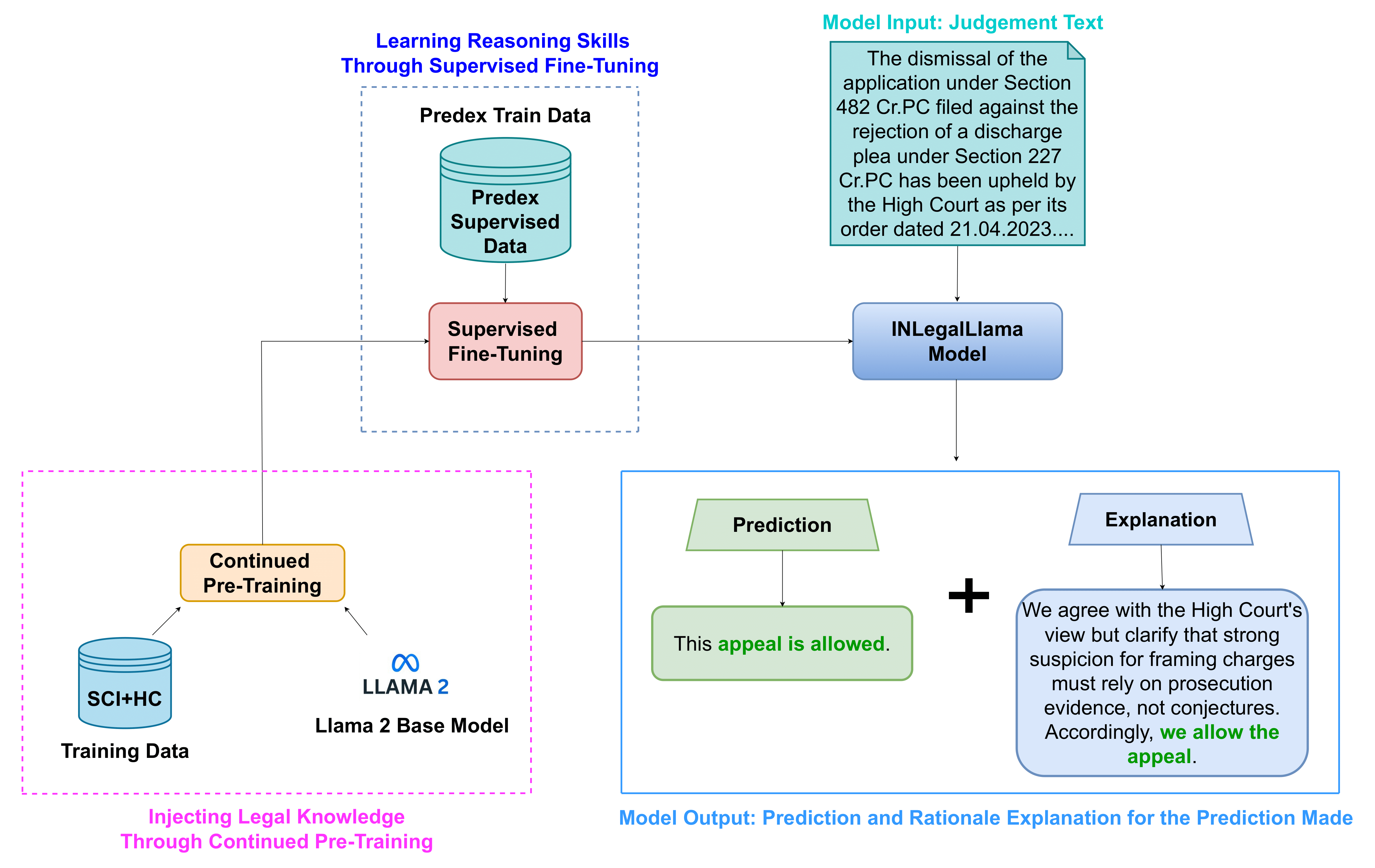
INLegalLlama training and Inference pipeline.
Implications and Future Directions
The work addresses India’s judicial backlog by automating judgment prediction while maintaining transparency through explanations. Future steps include expanding the dataset to regional languages (e.g., Hindi, Bengali) and refining quantization techniques for larger models. The authors emphasize ethical AI deployment, advocating human oversight and open access via GitHub. The INLegalLlama model is available on Hugging Face, and the NyayaAnumana dataset is accessible through Huggingface. This initiative aims to democratize legal AI research and applications in India, fostering collaboration and innovation in the field.