LegalSeg: Unlocking the Structure of Indian Legal Judgments Through Rhetorical Role Classification
Structuring Judicial Text through Rhetorical Roles
Indian court judgments are lengthy, complex, and composed of diverse sections serving different purposes—such as presenting facts, arguments, legal reasoning, and decisions. To analyze these documents more effectively, each sentence can be labeled with a rhetorical role, helping distinguish between the various components of the legal narrative. This kind of annotation supports better organization, retrieval, and interpretation of legal texts, making it easier to automate tasks like summarization and precedent extraction.
LegalSeg Model Explanation and Interface Overview

Document segmentation into rhetorical roles.
A Large-Scale Annotated Corpus for Indian Legal Judgments
A dataset of over 7,000 Indian legal case documents has been annotated at the sentence level, comprising more than 300,000 sentences tagged with seven rhetorical roles. These roles include Facts, Arguments, Ratio, Ruling by Precedent, Ruling by Present Court, Precedent, and Statute. The annotations were curated by legal experts using a taxonomy grounded in legal theory. This corpus captures the structural and rhetorical richness of Indian legal documents, addressing a gap in global legal NLP resources. It enables the development and benchmarking of models for understanding the semantic flow of legal judgments in India's diverse legal system.
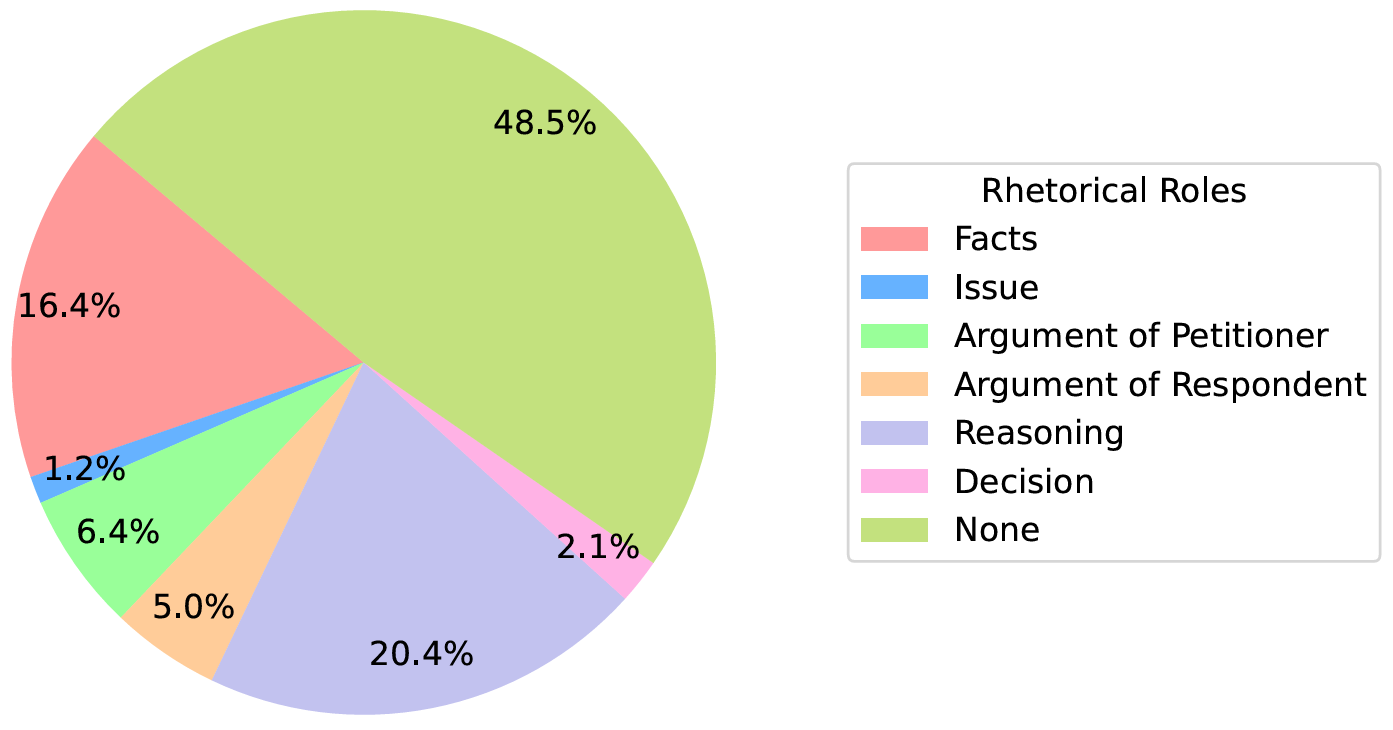
Distributon of rhetorical roles in the dataset.
Challenges in Legal Role Classification
Despite promising results, rhetorical role classification in legal documents remains a non-trivial task due to several inherent challenges. First, some rhetorical categories are semantically close, making it difficult even for human annotators to distinguish them reliably. For example, “Ratio” (reasoning) and “Ruling by Present Court” may share similar language and logical structure. Second, the dataset suffers from class imbalance, where roles such as “Facts” occur far more frequently than roles like “Precedent” or “Statute.” This imbalance can lead models to be biased toward predicting the dominant classes, thereby reducing their accuracy on the underrepresented ones. Additionally, legal language is often formal, archaic, and context-dependent, which makes it difficult for general-purpose language models to perform well without domain-specific tuning. Addressing these issues requires not just improved modeling techniques but also thoughtful annotation guidelines, better sampling strategies, and domain-aware model pretraining.
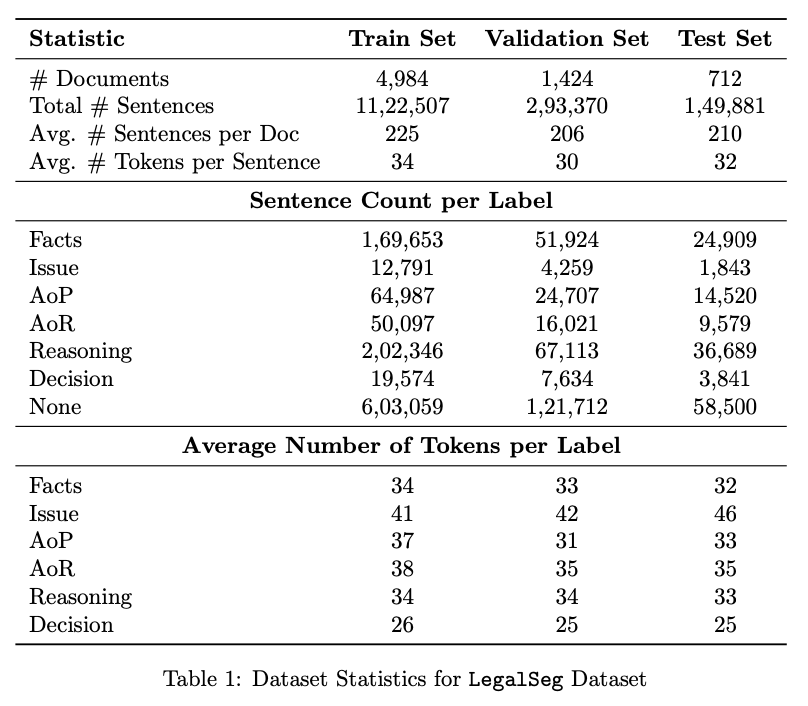
Dataset statistics.
Comparing Modeling Approaches for Role Classification
Various machine learning models have been evaluated for rhetorical role classification in legal texts. Traditional models like BiLSTM-CRF provide a baseline, while transformer-based models such as BERT and Longformer achieve better results by leveraging deeper contextual understanding. Advanced approaches like hierarchical and graph-based models further enhance performance by capturing inter-sentence dependencies and document structure. Instruction-tuned LLMs demonstrate strong zero-shot and few-shot capabilities but are outperformed by models that incorporate structural cues. This analysis highlights the trade-offs between computational resources, training data, and model performance.
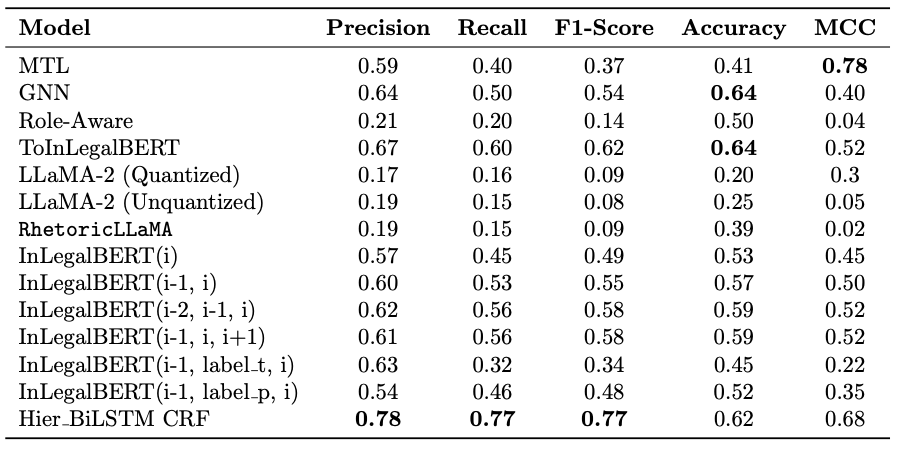
Performance of different models trained on LegalSeg dataset.
Implications for Legal AI and Document Understanding
Automatically identifying rhetorical roles in legal texts enables smarter legal information systems. These tools improve summarization, precedent detection, and argument mining, helping legal professionals handle complex judgments more efficiently. Applying them to Indian cases supports broader efforts to digitize and democratize legal knowledge. This also sets the stage for future research in areas like multilingual legal processing and automated compliance. Overall, it moves us closer to making law more accessible and technology-driven.