Legal Judgment Reimagined: PredEx and the Rise of Intelligent AI Interpretation in Indian Courts
Creation of the PredEx Dataset
PredEx comprises 15,222 annotated Indian legal cases from the Supreme Court and High Courts, meticulously curated to include both binary judgment predictions (accept/reject) and expert-written explanations. Legal students and professionals annotated key sentences influencing decisions, ensuring balanced representation across case types and outcomes. The dataset’s preprocessing involved removing ambiguous or overly brief cases, resulting in a robust 80-20 train-test split. This resource addresses gaps in prior datasets like ILDC by prioritizing explanatory depth alongside prediction, enabling models to learn context-aware legal reasoning.
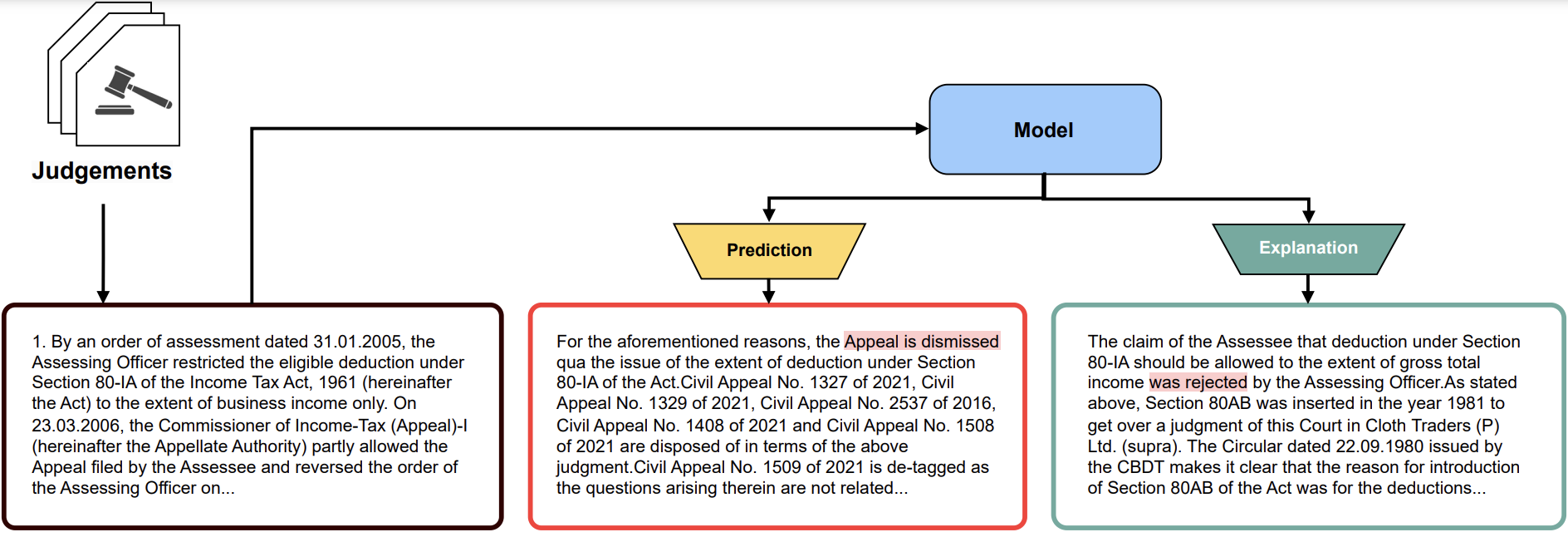
High-level pipeline for the project.
Instruction-Tuning for Legal LLMs
The methodology leverages instruction-tuning on LLMs like Llama-2-7B, tailoring prompts to predict outcomes and justify decisions using case proceedings. Training involves two phases: fine-tuning on PredEx for prediction and integrating explanation-specific instructions to mimic judicial reasoning. Models process 512-token chunks with overlapping windows to handle lengthy documents, prioritizing the final 1,000 tokens for contextual relevance. This approach reduces hallucinations and improves coherence, achieving 76.05% accuracy in explanation tasks compared to baseline models like GPT-3.5 and vanilla Llama-2.
Dual-Task Framework for Prediction and Explanation
A novel dual-task framework simultaneously predicts case outcomes and generates explanations by identifying pivotal legal arguments. Lexical metrics (ROUGE, BLEU) and semantic similarity scores (BERTScore) validate explanation quality, while expert evaluations using a 1–5 Likert scale assess practical utility. The framework’s strength lies in its ability to highlight statutory references, precedent citations, and judicial logic from case texts. For example, models trained on PredEx show 10–15% accuracy gains over ILDC-trained counterparts, demonstrating superior generalization across diverse court hierarchies and temporal ranges (2020–2024).
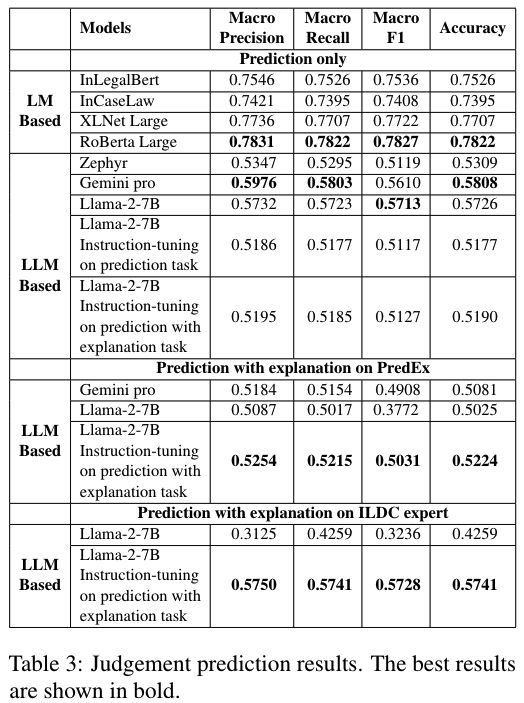
Results
Ethical and Practical Implications
The study emphasizes ethical AI deployment, advocating human oversight to mitigate risks of erroneous or biased predictions. By open-sourcing PredEx and model code, the work encourages reproducibility and further research into regional language adaptations (e.g., Hindi, Bengali). Future directions include reinforcement learning from human feedback (RLHF) to refine explanations and quantization techniques for deploying larger models. These efforts aim to reduce India’s judicial backlog while ensuring AI complements, rather than replaces, human legal expertise.
Evaluation and Mitigation of Hallucinations
Rigorous evaluations reveal instruction-tuned models reduce hallucination rates by ~40% compared to pre-trained LLMs, as measured by expert reviews. Post-processing filters truncate repetitive or contradictory outputs, ensuring coherence in predictions and explanations. Semantic metrics like BERTScore (0.69) confirm alignment with ground-truth reasoning, while temporal validation tests prove model robustness on future cases. The integration of domain-specific knowledge during fine-tuning addresses limitations in general-purpose LLMs, enabling reliable application in high-stakes legal contexts.